This is a guest post from Alice Allen, primary editor of the Astrophysics Source Code Library (ASCL).
Last September, I introduced and described the Astrophysics Source Code Library, a free on-line registry for source codes. I’m happy to report that ASCL is now indexed as a publication by ADS! This provides a reliable and consistent way for codes to be cited and is an important step in giving coders more recognition for their work.
Each ASCL record in ADS shows the title of the code, the list of authors, the publication date (the date the code was entered in the ASCL), the publication (Astrophysics Source Code Library), and record number. The record number is a unique code that is assigned to each citeable entry in the ASCL. Codes can be listed in the bibliography as [author], [year], [code name], ASCL [ascl ID number]. For example: Nemiroff, R. J. 1999, BHSKY, ASCL 9910.006.
For example, searching ADS for the code “Funtools” (don’t you just love that? Funtools! What a great name for a code!) brings up two entries:
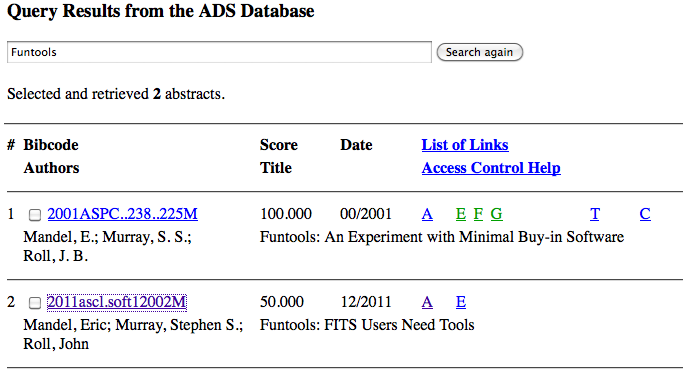
The first result is a conference proceeding but the second one, with the “ascl.soft” bibcode, is the entry for the code itself! Clicking on it brings up the full record:
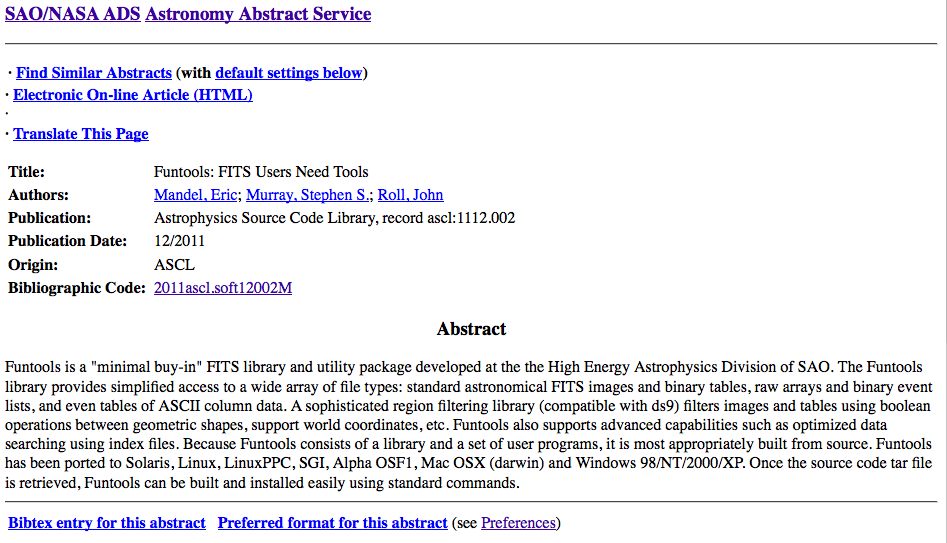
Clicking on “Electronic On-line Article (HTML)” takes you to the entry for this code in the ASCL. You can also use the ascl id to find the permalink to the ASCL entry for this code: http://ascl.net/1112.002
Additional information about the ACSL is available in the online Guide to the ASCL, our poster handout (PDF) and on our new FB page. If the information you seek isn’t there, please just ask!
Also, I’ve started a Facebook page for the ASCL. This page is intended for news updates, general feedback, and answers to questions about the ASCL. However, if people wanted to use it to discuss their favorite code, that would be great too!
And we are of course always looking to add more codes! Suggest codes that need to be added in the New codes welcome thread or post your own.
the link in the original paper has not rotted out so think there are better examples where ASCL can serve the community. the case I am thinking of concern what I call “embargoed” codes: ones that are discussed in papers sans a URL, ones whose original URL has rotted out, ones where people are protected their purported IP by requiring you to email the to get the code.
another (more interesting to me) subset would be where codes have no corresponding citable paper though maybe they should have a citable paper to explain the details. There are many examples from bio: PLoS Comp Bio or BMC’s Open Research Computation. Its like data citations — if the paper explains the code and links (accurately) to it then maybe that should be the correct citation to use.
i would also hope that a kin to CDS catalog citations (the “yCat” kind) ADS eventually groups original and code citations so users do not get the impression that the post publication curated resource stands alone.
Hi Alice, thanks for writing about the ASCL. It definitely looks like a carefully scrutinized, gigantic undertaking. I’m a contributor on two codes that are both featured in the ASCL, which brought up a couple points I was hoping you could clarify. (Gus pointed me to this post from Google+.)
The first code is one that I started, called yt, which is an analysis and visualization package. It has evolved a lot over the last couple years, which is part of why I bring it up. The entry on ASCL:
http://asterisk.apod.com/viewtopic.php?f=35&t=22098
is very similar to the ADS entry for our ApJS paper:
http://adsabs.harvard.edu/abs/2011ApJS..192….9T
In fact, it almost looks like the abstract was scraped, removed of the URL to the code homepage, and then the author list was copied. This now shows up as an entry in ADS for a query of my name, with an identical title to the ApJS paper — which I did not know would be happening until I saw it when doing a self-query to update my CV a few weeks ago. Are there going to be (mostly) duplicate entries for each code submitted? If so, what is the citation methodology you see being the best — to encourage people to cite the ASCL, or to cite something like ApJS?
The second question is more related to how the ASCL views a “code.” I will use both yt, mentioned above, and another code that I contribute to called “Enzo” which is a simulation code, as examples. In the time since yt was posted to the arXiv, the number of contributors has more than doubled. However, the “credit” listing in the ASCL lists only those who were authors on the original ApJS paper (and whose names may not even appear in the changelog or ‘hg churn’ from the repository.) Do you see the ASCL serving as a method for updating contributor information to a code? I am of the opinion, which I think is warranted, that viewing a scientific code as a single, fixed object is misguided; codes are updated with bug fixes, new features, modifications to underlying assumptions, and on and on. They are better viewed as rivers, rather than as lakes. One of the thing these codes do with time is update the number of contributors, the names of those contributors, their relative importance, and so on. This brings me to the second point, which is that of the code Enzo:
http://asterisk.apod.com/viewtopic.php?f=35&t=21812
Enzo is no longer best viewed as credited only to those individuals; does that mean that the record, in both ADS and ASCL, should be updated with new information, wherein each contributor be listed? If so, what does that change about the entries that exist in BibTeX files and bibliographies out there already? (Does ADS like to update authorship?) With journal articles, there is a fixed point when the paper is released: it has a date, the journal does not update that, and that is how credit, authorship, etc are assigned — no matter how many people get added to yt or to Enzo’s changelogs, the articles that were published in 1997 (the canonical Enzo citation, Bryan & Norman 1997), 2004 (the Enzo citation above) and 2011 (the yt paper above) do not change, but they are not *expected* to change, either. In a system designed for tracking source code, do the same assumptions apply? It seems to me that there is an opportunity here, to move past the peer-reviewed fixed-point credit of source code.
Nominally software is released and has versions. In which case, it would be great to see version numbers attached as part of the citation in the interest of reproducibility.
But I am getting the sense now that the release system is falling by the way side in exchange for public source repositories that can be downloaded and compiled anytime. I don’t know how to handle that… any ideas?
I’d like to echo some of Matt’s excellent points/questions. A decent number of astronomy codes (especially for python) are open source and have essentially a never-ending development cycle. As an example, the plan for Astropy involves some packages that start out independent eventually merging into the astropy project. Does that mean that we should make sure these initial projects stay alive so that their authors get credit for their contributions to the core package? For that matter, how is the core best treated, given that the author list is a perpetually-evolving thing?
This may end up just a limitation imposed by how ADS operates, but it would be good to know if these things can be dealt with…
Wow, comments! Cool! (Thanks!)
Gus, the most important reason for having a resource such as the ASCL is reproducibility: codes used for peer-reviewed research should be open for examination. This has been discussed in a number of articles and papers (Barnes 2010; Wiener et al 2009; de Winter, 2010; Stewart, Almes, & Wheeler, 2010, and many others); Teuben’s ADASS XXI presentation on codes (preprint here: http://arxiv.org/abs/1202.1026) covers this, too. (See also here for other papers: http://asterisk.apod.com/viewtopic.php?f=35&t=21544)
That said, I absolutely agree with you that there are other ways the ASCL can serve the community! The ASCL can house archive files of codes; if a coder doesn’t want to maintain a download site for a code, that’s okay — the ASCL can serve that function, and does already for a few codes.
(As you mentioned, some codes are available only by requesting the code from the author; so long as the ASCL can list the email address of the author, I’ll include that code in the ASCL.)
Many codes do not have a “code paper” that describes the code. Those which do, yes, it makes sense to cite that paper. We seek to make codes citable even when they do not have such a paper. And we think coders could be granted a little more recognition for their work, too!
Matthew, I love it when a code is described as well as yt is! (Thank you!) Yes, there will be duplicate entries for some codes such as yt. (yt was early-on in my work on the ASCL; I’m more prone to tailoring the information a bit now.)
On citations, I think we will have to see how they go. Does the community need a consistent way of citing codes? The ASCL provides one option; it’s not intended to compete with journals, however, but rather to complement them. The important thing is having a reliable way to let people know what was used, and how to find it.
Matthew and Erik, re: authorship, in some cases an ASCL entry refers to the list of contributors on the download site rather than listing all contributors. I’m open to suggestions as to how better to handle codes with an ongoing development cycle while pointing out what you already know: there are going to be limitations at some point.
Long enough for now? Likely yes; I hope I answered all questions, but if not, please let me know. Thanks!
Jessica, my apologies; I missed your comment. Some codes are no longer being updated (or maybe never were updated after an initial release). For codes which do have different releases, however, IMO research using the code should specify the version number.
Matt raises an excellent point about authorship and ongoing development, and I think possibly Alice’s answer contains the germ of a solution.
Of course, it’s completely correct that much software now is a continuous effort: it’s not frozen at one particular “fixed-point” like a publication is. However, any published research which was performed using that software did make use of a particular version (or versions). Alice correctly identifies reproducibility as an important goal: in order for that research to be reproducible, it’s necessary not only to cite the code used but to cite the particular version of that code. Otherwise, some new version of the code may have fixed (or introduced…) a particular bug, and tracking down how to reproduce the work in question becomes impossible.
So what does that mean? Well, as Alice says it’s not enough for a paper just to say “we made use of Enzo” (for example); it should say “we made use of Enzo version X”, where X has a well defined contents, authorship, and so on; and there’s your fixed-point that can be indexed. But is that something a facility like ASCL can help with? Is it reasonable to expect Alice and her colleagues to not merely list all the codes they can find, but all the versions of those codes? That sounds like a mammoth task. If that’s not practical, is ASCL just a link farm — you can use it as a “persistent URL” for a code, but will always need to follow that URL and investigate the source repository (if it’s available) to understand the versioning scheme and who contributed to it? Is there some smarter middle way? I’m not sure…
With regards to citing open-source codes that are distributed via version control, there’s a simple mechanism to specify precisely the version of the code you’re using. In Mercurial, every changeset has a revision number and a hash associated with it (“hg summary”), so you can specify in papers precisely what version of the code it is. See http://xxx.lanl.gov/abs/1011.2632 for an example of this (footnote 8, on the second page of the paper). In that way, somebody could go and retrieve the exact version of the code you used, even if it has been changed since then. Other version control systems have revision IDs/changesets/hashes as well. So, if we can get into the habit of stating which changeset we’re using in our code, that would go a long way toward addressing some of the concerns expressed!
“Well, as Alice says it’s not enough for a paper just to say “we made use of Enzo” (for example); it should say “we made use of Enzo version X”, where X has a well defined contents, authorship, and so on; and there’s your fixed-point that can be indexed.”
Some papers don’t mention codes used in the research at all; I’ll take “we made use of Enzo” over that! Better would be “Enzo version X,” of course, but if it’s not required…
“But is that something a facility like ASCL can help with?”
Probably not, and there may be little need to. Many coders leave previous versions of their codes available on their code webpages, and there’s no utility to tracking versions in the ASCL entry. We do encourage people to post to the thread for their code when there’s a new version of the code available, but that doesn’t happen very often. Yet. 🙂
“…is ASCL just a link farm…”
Yes, the ASCL is primarily a link farm, or digital card catalog. Various similar efforts, including the ASCL when it was founded, had tried to serve as code repositories; that didn’t work. Most coders prefer to keep their codes close to them. The other similar efforts still in existence depend on coders to list their codes on the site; originally, the ASCL relied on coders to add their codes (or submit them, or list information about them, etc.), too. That hasn’t worked either, though might work (at least somewhat) in the future when there’s some payback or community expectation for or practice of adding one’s code. That will be our tipping point! I can see it out there; it beckons! But right now, we have to chase it; associate editor Kim and I will continue seeking out codes to add to the ASCL to chase down that tipping point.
In the meantime, we have a list of perhaps 200 codes we haven’t yet had time to research. Code Zoo, anyone? 😀
this is a little beyond the pale but…
can you do quick statistics on the URLs for the codes? what fraction have:
1. no link to a repository
2. link to a major repository (code.google, github, sourceforge)
3. link to a .edu website
4. link somewhere else
5. a broken link that you have been unable to recover?
The reason I ask is because for #2 there are APIs to the repositories that enable rich reuse of the meta-data about the code (version, authors, forks, last updated, issue tracking) perhaps even right in the ASCL entry.
If citation were to re-enforce any cultural behaviors I would hope it would be to put data in shared repositories and not just anywhere because you know someone might curate it someday.
Similarly, I think ADS should expose the actual software links right in the citation.
freudian slip — “hope it would be to put
datacode in shared repositories”Gus, not beyond the pale at all! I can’t do it right now, but yes, I should be able to pull some quick stats. On broken links, we do test the links periodically. I think the right place for most of the metadata you list is on the code’s website rather than in the ASCL because that kind of metadata undergoes many changes. My focus is on many codes perhaps thinly described rather than fewer codes richly described. Of course I’d love to have all codes richly described, but it’s a time thing: there just isn’t enough of it.
I’ll talk to ADS about putting the actual software links right in the citations; I don’t know whether they can accommodate them or not, but will find out.